As Large Language Models (LLMs) evolve from standalone chatbots into autonomous agents integrated into enterprise workflows, their ability to retain context and learn from interactions becomes critical. However, this capability introduces a new, sophisticated attack surface: Memory Pollution. This article explores the architecture of LLM memory, the mechanics of memory pollution, and the real-world security implications of compromised AI memory.
Memory is the cornerstone of both human cognition and LLM agency. Without memory, an LLM is stateless—limited to a single interaction with no continuity. With memory, LLMs transform into personalized, context-aware assistants capable of remembering user preferences, maintaining multi-session coherence, and executing complex, long-term tasks.
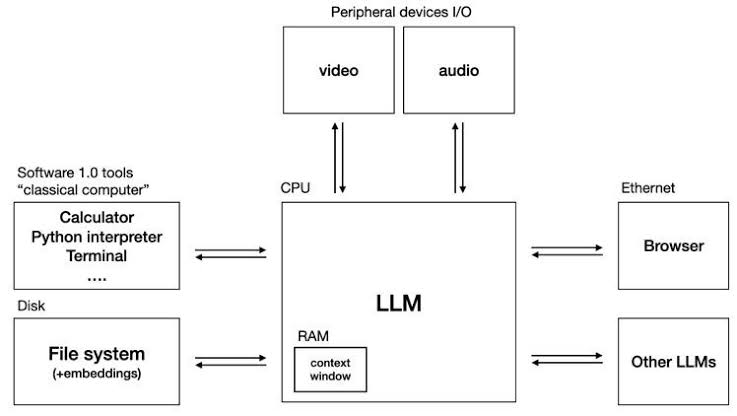
This concept aligns with Andrej Karpathy’s "LLM OS" vision, where the LLM acts as the central processing unit of a new operating system. In this paradigm, just like in traditional computing, memory is not just a feature; it is a foundational infrastructure component required for the system to function, communicate, and learn. When this memory is compromised, the entire operating system is at risk.
To understand memory pollution, we must first map LLM memory to traditional computing architecture:
Short-term memory functions like RAM. It is the temporary context window that holds the current conversation, system prompts, and retrieved documents. Once the session ends or the context limit is exceeded, this memory is wiped. It is fast but volatile.
Long-term memory functions like a Hard Drive or Cloud Storage. It involves durable, external storage solutions that retain information across sessions. This allows the model to recall past interactions and user preferences. This layer typically consists of:
Memory pollution occurs when an adversary successfully injects untrusted, malicious, or fabricated data into the LLM’s persistent memory. Once polluted, the LLM operates with a compromised "worldview," leading to systemic failures in future interactions.
Because long-term memory is queried to augment future responses, a single successful pollution attack can persist indefinitely, silently degrading the model's reliability and security posture across all future user interactions.
Memory pollution doesn't happen by accident; it is the result of specific adversarial techniques:
The diagram below illustrates how user queries interact with LLM memory, highlighting the critical decision point: how data is saved.
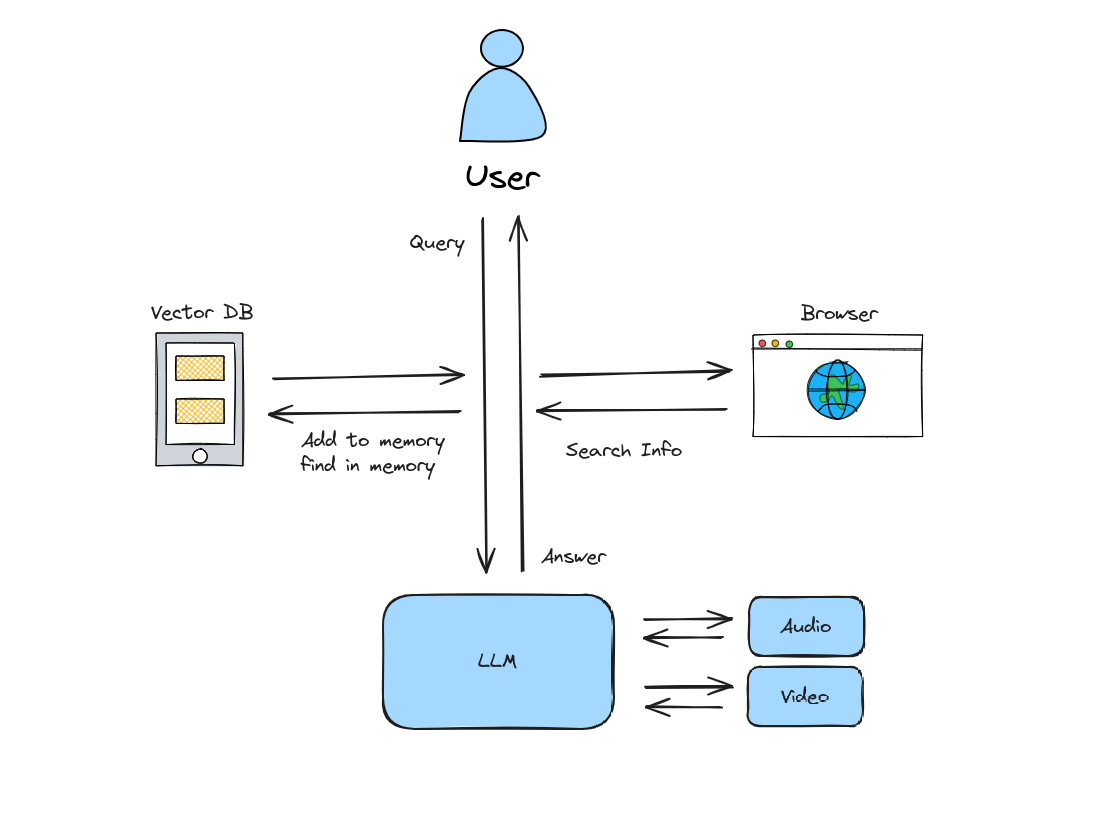
In this setup, the LLM autonomously writes to persistent memory without user verification to reduce friction.
User: Who is the CEO of TechCorp?
Bot: The CEO of TechCorp is John Doe. This information has been automatically saved to long-term memory.
The Risk: If the bot retrieved this from a compromised source or a poisoned webpage, the false information is now permanent. Future queries about TechCorp will confidently return the wrong CEO, leading to direct operational decision-making errors based on poisoned data assets.
In this setup, the LLM requests explicit consent before committing data to memory.
User: Who is the CEO of TechCorp?
Bot: The CEO of TechCorp is John Doe. Would you like to save this information to your long-term memory?
User: Yes, please save it.
Bot: Done! The information has been saved to long-term memory.
The Benefit: While this introduces friction, it provides a human-in-the-loop moderation layer. It allows users to verify the source and accuracy of the data before it becomes a persistent hallucination, significantly mitigating the risk of long-term data poisoning.
2024-05-22 - v1.0
2024-05-24 - v1.1